The intention of this page is to provide some explanation
of the gedcom parser, to aid development on and with it. First,
@@ -151,56 +151,9 @@ the file.
This basic description ignores the problem of character encoding. The next section describes what this problem exactly is.
-
Character encoding
-
The character encoding problem
-
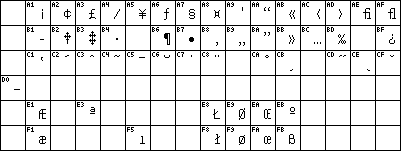
-Developers are usually familiar with the ASCII character set. This
-is a character set that assigns a unique number to some characters, e.g.
-an "A" has ASCII code 65 (or 0x41 in hex), and an "a" has ASCII code 97 (or
-0x61 in hex). Some people may also have used ASCII codes for several
-drawing characters (such as a horizontal bar, a vertical bar, or a top-right
-corner) in the old DOS days, to be able to draw nice windows in text mode.
-
-However, these last characters are strictly spoken not part of the ASCII
-set. The standard ASCII set contains only the character positions from
-0 to 127 (i.e. anything that fits into an integer that is 7 bits wide). An
-example of this table can be found
here. Anything that has an ASCII code between 128 and 255 is in principle undefined.
-
-Now, several systems (including the old DOS) have defined those character
-positions anyway, but usually in totally different ways. Some well
-known extensions are:
-
- - the DOS
- character set, nowadays usually known as Code Page 437, but sometimes also
-named LatinUS, ECS (Extended Character Set) or PC-8; note that the table
-displayed in the link also contains the standard ASCII part
- - the ANSI character set, also known as Code Page 1252, and usually the default on Windows
- - the ISO-8859-1 character set (also called Latin-1), which is an ISO standard for Western European languages, mostly used on various Unices
- - the Adobe Standard Encoding, which is by default used in Postscript, unless overridden
-
-And these are only examples of character sets used in West-European languages.
- For Japanese, Chinese, Korean, Vietnamese, ... there are separate character
-sets in which one byte's meaning can even be influenced by what the previous
-byte was, i.e. these are multi-byte character sets. This is because
-even 256 characters is totally inadequate to represent all characters in
-such languages.
-
-So, summarizing, if a text file contains a byte that has a value 65, it is
-pretty safe to assume that this byte represents an "A", if we ignore the
-multi-byte character sets spoken of before. However, a value 233 cannot
-be interpreted without knowing in which character set the text file is written.
- In Latin-1, it happens to be the character "é", but in another
-character set it can be something totally different (e.g. in the DOS character
-set it is the Greek letter theta).
-
-Vice versa, if you need to write a character "é" to a file, it depends
-on the character set you will use what the numerical value will be in the
-file: in Latin-1 it will be 233, but if you use the DOS character set it
-will be 130.
-
-
Unicode
-Enter the Unicode standard...
-
+
Character encoding
Refer to
this page for some introduction on character encoding...
+
+
TO BE COMPLETED
{kind=link}
{kind=link}
{kind=link}
{kind=link}