Gedcom parser in Genes
- -The intention of this page is to provide some explanation
- of the gedcom parser, to aid development on and with it. Currently,
- the parser is in a state that it works, but some parts are still missing,
- notably the interface towards applications. First, some practical
-issues of testing with the parser will be explained.
-
- -Basic testing
- The parser is located in the "gedcom" subdirectory of the Genes source
- code. You should be able to perform a basic test using the commands:
- -
-
- -
-
- However, since the output that
-
- For the first issue, the UTF-8 capable terminal, the safest bet is to - use
-
- For the second issue, you'll need the ISO 10646-1 fonts. These -come also with XFree86 4.0.x.
-
- The way to start
- -
-
- -
- -
-
- For the ANSEL test file (
+ +The Gedcom parser library
+
+
+
+
+ + This is because for the ANSEL character set an extra module is needed + for the iconv library (more on this later). But again, this should + show a lot of special characters.
+
+ + +
+ +
+
+ This concludes the testing setup. Now for some explanations...
+
+ + +
+
+ +
+
+
+
+ The parser is based on
+
+For each recognized statement in the GEDCOM file, the parser calls some callbacks, +which can be registered by the application to get the information out of +the file.
+
+This basic description ignores the problem of character encoding. The next section describes what this problem exactly is.
+
+The character encoding problem
+Developers are usually familiar with the ASCII character set. This
+is a character set that assigns a unique number to some characters, e.g.
+an "A" has ASCII code 65 (or 0x41 in hex), and an "a" has ASCII code 97 (or
+0x61 in hex). Some people may also have used ASCII codes for several
+drawing characters (such as a horizontal bar, a vertical bar, or a top-right
+corner) in the old DOS days, to be able to draw nice windows in text mode.
+
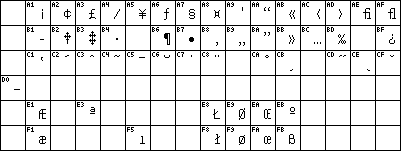
+However, these last characters are strictly spoken not part of the ASCII +set. The standard ASCII set contains only the character positions from +0 to 127 (i.e. anything that fits into an integer that is 7 bits wide). An +example of this table can be found here. Anything that has an ASCII code between 128 and 255 is in principle undefined.
+
+Now, several systems (including the old DOS) have defined those character +positions anyway, but usually in totally different ways. Some well +known extensions are:
+
+
+So, summarizing, if a text file contains a byte that has a value 65, it is +pretty safe to assume that this byte represents an "A", if we ignore the +multi-byte character sets spoken of before. However, a value 233 cannot +be interpreted without knowing in which character set the text file is written. + In Latin-1, it happens to be the character "é", but in another +character set it can be something totally different (e.g. in the DOS character +set it is the Greek letter theta).
+
+Vice versa, if you need to write a character "é" to a file, it depends +on the character set you will use what the numerical value will be in the +file: in Latin-1 it will be 233, but if you use the DOS character set it +will be 130.
+
+
+
+TO BE COMPLETED
+ - - +
+
+
+ -
- -
Basic testing
-
- The parser is located in the "gedcom" subdirectory of the Genes source
- code. You should be able to perform a basic test using the commands:- -
- If everything goes OK, you'll see that some gedcom files are parsed, -and that each parse is successful. Note that the used gedcom files -are made by Heiner -Eichmann - and are an excellent way to test gedcom parsers thoroughly.make clean
- make
- make test
-
-
- -
Preparing for further testing
- The basic testing described above doesn't show anything else than "Parse - succeeded", which is nice, but not very interesting. Some more detailed - tests are possible, via thegedcom-parse program that is generated
- by make test. -
- However, since the output that
gedcom-parse generates is
- in UTF-8 format (more on this later), some preparation is necessary to
-have a full view on it. Basically, you need a terminal that understands
-and can display UTF-8 encoded characters, and you need to proper fonts installed
- to display them. I'll give some advice on this here, based on the
-Red Hat 7.1 distribution that I use, with glibc 2.2 and XFree86 4.0.x. Any
- other distribution that has the same or newer versions for these components
- should give the same results.-
- For the first issue, the UTF-8 capable terminal, the safest bet is to - use
xterm in its unicode mode (which is supported by the
- xterm coming with XFree86 4.0.x). UTF-8 capabilities
- have only recently been added to gnome-terminal, so probably
- that is not in your distribution yet (it certainly isn't in Red Hat 7.1).-
- For the second issue, you'll need the ISO 10646-1 fonts. These -come also with XFree86 4.0.x.
-
- The way to start
xterm in unicode mode is then e.g. (put
- everything on 1 line !):- -
- This first sets theLANG=en_GB.UTF-8 xterm -bg 'black' -fg 'DarkGrey' -cm - -fn '-Misc-Fixed-Medium-R-SemiCondensed--13-120-75-75-C-60-ISO10646-1'
-
LANG variable to a locale that
-uses UTF-8, and then starts xterm with a proper Unicode font.
- Some sample UTF-8 plain text files can be found
- here
- . Just cat them on the command line and see the result.-
- -
Testing the parser with debugging
- Given the UTF-8 capable terminal, you can now let thegedcom-parse
- program print the values that it parses. An example of a command
- line is (in the gedcom directory):- -
- The./gedcom_parse -dg t/ulhc.ged
-
-dg option instructs the parser to show its own debug
- messages (see ./gedcom_parse -h for the full set of
-options). If everything is OK, you'll see the values from the gedcom
-file, containing a lot of special characters.-
- For the ANSEL test file (
t/ansel.ged), you have to set the
- environment variable GCONV_PATH to the ansel subdirectory
- of the gedcom directory:+ +
+
+ ./testgedcom -dg t/ansel.gedThe Gedcom parser library
+ +The intention of this page is to provide some explanation
+ of the gedcom parser, to aid development on and with it. First,
+some practical issues of testing with the parser will be explained.
+
+
+
+Testing
+
+
+Basic testing
+
+ You should be able to perform a basic test using the commands:
+ +
+
+ + +
+
+ However, since the output that
+
+ For the first issue, the UTF-8 capable terminal, the safest bet is + to use
+
+ For the second issue, you'll need the ISO 10646-1 fonts. These + come also with XFree86 4.0.x.
+
+ The way to start
+ +
+
+ + +
+ +
+
+ For the ANSEL test file (
+
-
- -
- -
-
- This concludes the testing setup. Now for some explanations...
-
- -
-
-
-
-
-
- TO BE COMPLETED...
- -
$Id: parser.html,v 1.2 2001/12/01 15:29:00 -verthezp Exp $
- $Name$
-
-
- +
+
Index
+-
+
- Testing +
- Basic testing +
- Preparing for further testing +
- Testing the parser with debugging +
- Testing the lexers separately
+
+ - Structure of the parser +
- Character encoding
+
+
-
+
-
+
+
+
Testing
+
+
+
+Basic testing
+
+
+
+ You should be able to perform a basic test using the commands:+ +
+ If everything goes OK, you'll see that some gedcom files are parsed, + and that each parse is successful. Note that some of the used gedcom files + are made by Heiner + Eichmann and are an excellent way to test gedcom parsers thoroughly../configure
+ make
+ make check
+
+
+ + +
Preparing for further testing
+Some +more detailed tests are possible, via thetestgedcom program
+that is generated by make. +
+ However, since the output that
testgedcom generates
+is in UTF-8 format (more on this later), some preparation is necessary
+to have a full view on it. Basically, you need a terminal that understands
+ and can display UTF-8 encoded characters, and you need to proper fonts
+installed to display them. I'll give some advice on this here,
+based on the Red Hat 7.1 distribution that I use, with glibc 2.2 and XFree86
+4.0.x. Any other distribution that has the same or newer versions
+for these components should give the same results.+
+ For the first issue, the UTF-8 capable terminal, the safest bet is + to use
xterm in its unicode mode (which is supported by
+the xterm coming with XFree86 4.0.x). UTF-8 capabilities
+ have only recently been added to gnome-terminal, so probably
+ that is not in your distribution yet (it certainly isn't in Red Hat 7.1).+
+ For the second issue, you'll need the ISO 10646-1 fonts. These + come also with XFree86 4.0.x.
+
+ The way to start
xterm in unicode mode is then e.g.
+(put everything on 1 line !):+ +
+ This first sets theLANG=en_GB.UTF-8 xterm -bg 'black' -fg 'DarkGrey' -cm + -fn '-Misc-Fixed-Medium-R-SemiCondensed--13-120-75-75-C-60-ISO10646-1'
+
LANG variable to a locale that
+ uses UTF-8, and then starts xterm with a proper Unicode font.
+ Some sample UTF-8 plain text files can be found
+ here . Just cat them on the command line
+ and see the result.+
+ + +
Testing the parser with debugging
+ + Given the UTF-8 capable terminal, you can now let thetestgedcom
+ program print the values that it parses. An example of a command
+ line is (in the gedcom directory):+ +
+ The./testgedcom -dg t/ulhc.ged
+
-dg option instructs the parser to show its own debug
+ messages (see ./testgedcom -h for the full set of options).
+ If everything is OK, you'll see the values from the gedcom file,
+containing a lot of special characters.+
+ For the ANSEL test file (
t/ansel.ged), you have to set
+ the environment variable GCONV_PATH to the ansel
+ subdirectory of the gedcom directory:+
export GCONV_PATH=./ansel
- ./gedcom_parse -dg t/ansel.ged
- -
- -
Testing the lexers separately
- The lexers themselves can be tested separately. For the 1-byte -lexer (i.e. supporting the encodings with 1 byte per characters, such as -ASCII, ANSI and ANSEL), the sequence of commands would be:- -
make clean
- make test_1byte
- t/allged.ged test file. Similar
-tests can be done using make test_hilo and make test_lohi
- (for the unicode lexers).-
- This concludes the testing setup. Now for some explanations...
-
- -
Structure of the parser
- I see the structure of a program using the gedcom parser as follows:-
-
- -
-
- TO BE COMPLETED...
- -
$Id: parser.html,v 1.2 2001/12/01 15:29:00 -verthezp Exp $
- $Name$
-
-
+ + This is because for the ANSEL character set an extra module is needed + for the iconv library (more on this later). But again, this should + show a lot of special characters.
+
+ + +
Testing the lexers separately
+ + The lexers themselves can be tested separately. For the 1-byte + lexer (i.e. supporting the encodings with 1 byte per characters, such as + ASCII, ANSI and ANSEL), the command would be (in thegedcom subdirectory):+ +
make lexer_1byte
+ t/allged.ged
+ test file. Simply cat the file through the lexer on standard input
+and you should get all the tokens in the file. Similar tests can be
+done using make lexer_hilo and
+make lexer_lohi (for the unicode lexers). In each of the cases you need to know yourself which of the test files are appropriate to pass through the lexer.+
+ This concludes the testing setup. Now for some explanations...
+
+ + +
Structure of the parser
+ I see the structure of a program using the gedcom parser as follows:+
+
+ +
+
+ The parser is based on
lex/yacc, which means that a module generated by lex
+ takes the inputfile and determines the tokens in that file (i.e. the smallest
+units, such as numbers, line terminators, GEDCOM tags, characters in GEDCOM
+values...). These tokens are passed to the parser module, which is
+generated by yacc, to parse the syntax of the file, i.e. whether the tokens
+appear in a sequence that is valid. +
+For each recognized statement in the GEDCOM file, the parser calls some callbacks, +which can be registered by the application to get the information out of +the file.
+
+This basic description ignores the problem of character encoding. The next section describes what this problem exactly is.
+
+
Character encoding
+The character encoding problem
+
+Developers are usually familiar with the ASCII character set. This
+is a character set that assigns a unique number to some characters, e.g.
+an "A" has ASCII code 65 (or 0x41 in hex), and an "a" has ASCII code 97 (or
+0x61 in hex). Some people may also have used ASCII codes for several
+drawing characters (such as a horizontal bar, a vertical bar, or a top-right
+corner) in the old DOS days, to be able to draw nice windows in text mode.+
+However, these last characters are strictly spoken not part of the ASCII +set. The standard ASCII set contains only the character positions from +0 to 127 (i.e. anything that fits into an integer that is 7 bits wide). An +example of this table can be found here. Anything that has an ASCII code between 128 and 255 is in principle undefined.
+
+Now, several systems (including the old DOS) have defined those character +positions anyway, but usually in totally different ways. Some well +known extensions are:
+
-
+
- the DOS + character set, nowadays usually known as Code Page 437, but sometimes also +named LatinUS, ECS (Extended Character Set) or PC-8; note that the table +displayed in the link also contains the standard ASCII part +
- the ANSI character set, also known as Code Page 1252, and usually the default on Windows +
- the ISO-8859-1 character set (also called Latin-1), which is an ISO standard for Western European languages, mostly used on various Unices +
- the Adobe Standard Encoding, which is by default used in Postscript, unless overridden +
{kind=link}
{kind=link}
{kind=link}
{kind=link}
+
+So, summarizing, if a text file contains a byte that has a value 65, it is +pretty safe to assume that this byte represents an "A", if we ignore the +multi-byte character sets spoken of before. However, a value 233 cannot +be interpreted without knowing in which character set the text file is written. + In Latin-1, it happens to be the character "é", but in another +character set it can be something totally different (e.g. in the DOS character +set it is the Greek letter theta).
+
+Vice versa, if you need to write a character "é" to a file, it depends +on the character set you will use what the numerical value will be in the +file: in Latin-1 it will be 233, but if you use the DOS character set it +will be 130.
+
+
Unicode
+Enter the Unicode standard...+
+TO BE COMPLETED
+ - - +
+
$Id$+
$Name$
+